Improve application resilience with Azure Chaos Studio
Breakdowns are inevitable; nowadays, developers are driven to consider built-in resilience an obligation rather than an option.
Chaos engineering disciplines developers to build confidence in systems and break systems on purpose so weaknesses can be found and fixed before they break when least expected. Deliberately introducing faults that simulate real-world outages is precisely what Azure Chaos Studio was designed for.
We’ll look at the Azure Chaos Studio service and its features. Then we’ll compare the service to other chaos engineering tools, followed by a step-by-step Azure Chaos Studio experiment.
Azure Chaos Studio
Azure Chaos Studio is Microsoft’s fully managed chaos engineering experimentation platform for accelerating the discovery of hard-to-find problems. It allows you to validate product quality by using the faults from the library, which include CPU pressure, network latency, blocked resource access, and even infrastructure outages.
At the time of writing, Azure Chaos Studio is in Public Preview. With the announcement on November 2, 2021, Microsoft has promised to add new faults to the fault library continuously.
Azure Chaos Studio drives application resilience by performing ad-hoc drills and integrations with your CI/CD pipelines. Chaos Studio uses Azure Resource Manager (ARM), which makes it easy to deploy and run your chaos experiments the same way you deploy and manage your infrastructure—leveraging ARM templates, Azure Policy, role-based access control, and more. Chaos Studio also integrates with Azure Application Insights and leverages Azure Active Directory for securing access to your resources. With Chaos Studio, you can easily stop an experiment and roll back the fault being injected to avoid having more impact on an environment than initially intended.
Fault types
With Chaos Studio, you create chaos experiments that allow you to orchestrate safe, controlled fault injection on your Azure resources. A chaos experiment describes the faults and the resources to run against.
Chaos Studio supports three types of faults:
- Service-direct faults: These faults run directly against an Azure resource without any installation or instrumentation. Examples include rebooting an Azure Cache for Redis cluster or blocking all network access to a Key Vault.
- Agent-based faults: These faults run in virtual machines or virtual machine scale sets for in-guest failures. They require the installation of the Chaos Studio agent. Examples include applying virtual memory pressure or killing a running process.
- Chaos Mesh faults: Run faults on Kubernetes clusters using Chaos Mesh. Chaos Mesh is an open-source chaos engineering platform for Kubernetes. It requires installing Chaos Mesh on your Azure Kubernetes Service (AKS) cluster. Examples include causing pod failures, container issues, and network faults like delays, duplications, loss, and corruption.
Chaos engineering tools comparison
Let’s look at other chaos engineering tools like ChaosBlade, Chaos Monkey, Gremlin, and Litmus. How does Azure Chaos Studio compare to these other chaos engineering tools?
ChaosBlade: If you’re looking for a wide range of experiment types and target platforms, managing experiments through CLI commands, Kubernetes manifests, or REST API calls, then ChaosBlade might be what you are looking for. It is modular, where the core tool is designed to be an experiment orchestrator, and the attacks are implemented separately. On the downside, if you are looking for detailed documentation, you better be able to read Standard Chinese because ChaosBlade lacks detailed English documentation.
Chaos Monkey: Chaos Monkey laid the foundation for chaos engineering tools. It only has one attack type: terminating virtual machine instances. It is deliberately unpredictable, giving you limited control over blast radius and execution when “releasing the monkey”. However, it creates the right mindset—preparing for disasters anytime.
Gremlin: Gremlin was the first managed enterprise chaos engineering service designed to improve reliability for web-based apps. It provides dozens of attack vectors, stops and rolls back attacks, and an integrated recommendation system. Gremlin allows customizable UI configurations, the ability for various attacks, simultaneously running tests, and automation support with a CLI and API. Unfortunately, Gremlin has no reporting capabilities, and although there is a free version, full software use requires a paid license and doesn’t come cheap.
Litmus: Litmus is a Kubernetes-related tool, providing many experiments for containers, Pods, nodes, and specific platforms and tools. Litmus includes a health checking feature, which lets you monitor the health of your application before, during, and after running an experiment. However, getting started with Litmus is much more complicated than most other tools. It requires you to create service accounts and annotations for each application and namespace you want to experiment on. This makes running experiments lengthy and complicated and gives you lots of administrative overhead when cleaning up experiments.
For the Azure-native software engineers, it becomes almost obvious that Azure Chaos Studio is the preferred choice. Particular requirements can lead to other chaos engineering tools based on specific characteristics. Ultimately, the tool will be just a resource to reach your goal faster and easier; achieve greater resilience.
Unleash chaos
Let’s deploy a simple AKS cluster and an app on which to run a chaos experiment so that you can familiarize yourself with Azure Chaos Studio. We’ll also cover the onboarding of the AKS cluster in Azure Chaos Studio and the creation of an experiment that causes pod failures. But before you can start deploying, there are some prerequisites to fulfill:
- Azure tenant and user account: You’ll need an Azure tenant, an Azure Active Directory (Azure AD) instance. This instance is the foundation of the environment. And it allows you to create an identity (user account) to connect to Azure, set up the environment, and deploy the resources.
- Subscriptions: You’ll need a subscription and owner permissions to deploy the resources and minimize the costs by removing the resources at the end.
- You’ll need to understand Azure Resource Groups and Azure Resource Manager (ARM) templates. You can find more information about ARM templates in the documentation.
- Azure CLI: You’ll need the Azure command-line interface for deploying the resources, and you can find more information about the Azure CLI in the documentation.
- Kubectl: You’ll need the Kubernetes command-line tool for deploying images and running other commands against your Kubernetes cluster. You can find more information about kubectl in the documentation.
- Helm: You’ll need the Helm command-line tool to deploy and configure applications and services. You can find more information about helm in the documentation.
Create the AKS cluster
First, we will deploy an AKS cluster to host our application. We’ll deploy the Azure Kubernetes Cluster by using an ARM template.
Step 1: Download the ARM templates from the supporting GitHub repository for the rest of this guide. Review and adjust the templates and commands when needed. We won’t be covering the details in this post.
Step 2: Start your preferred terminal and connect to Azure using the Azure CLI and your identity (user account).
az loginStep 3: List the available subscriptions and locate the preferred subscription ID.
az account list --output tableStep 4: Set the subscription you’re using to deploy the resources. Use the subscription ID from the previous step.
az account set --subscription <subscriptionId>Step 5: Set your environment variables and create a resource group.
$RESOURCE_GROUP_NAME="rg-t-aks-weu-chaos-robino-01"
$AKS_NAME="aks-t-weu-chaos-robino-01"
$DNS_PREFIX="aks-t-weu-chaos-robino-01-dns"
$LOCATION="westeurope"
$NODE_SIZE="Standard_B2s"
$DEPLOYMENT_NAME="AksDeploymentRobino-01"
az group create \
--name $RESOURCE_GROUP_NAME \
--location "$LOCATION"Step 6: Set the folder you’ve downloaded the ARM templates as your working directory and run the following code to deploy the cluster. Wait for the deployment to finish. This may take a couple of minutes.
az deployment group create \
--name $DEPLOYMENT_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--template-file "./aks-cluster.json" \
--parameters location=$LOCATION resourceName=$AKS_NAME dnsPrefix=$DNS_PREFIX agentCount=1 agentVMSize=$NODE_SIZEStep 7: Review what is deployed. You’ll find a resource group that contains the service, node pools, and networking. And that you have a separate resource group that contains the nodes, a load balancer, public IP addresses, network security group (NSG), managed identity, virtual network, and route table.
Deploy the web app
Now, we’ll deploy a sample app packaged into a container image and upload this to an Azure Container Registry. We’ll create the Azure Container Registry using the ARM template.
Step 1: Set the environment variables using your terminal from the previous steps.
$ACR_NAME="acrtaksweuchaosrobino01"
$DEPLOYMENT_NAME="AcrDeploymentRobino-01"Step 2: Run the following code to deploy the container registry using the ARM template. Wait for the deployment to finish. This may take a couple of minutes.
az deployment group create \
--name $DEPLOYMENT_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--template-file "./acr.json" \
--parameters registryLocation=$LOCATION registryName=$ACR_NAMEStep 3: Once the container registry is deployed, it’s time to import the container image of the sample application. Use the commands below to log in to your container registry and import the image.
az acr login -n $ACR_NAME --expose-token
az acr import --name $ACR_NAME \
--source mcr.microsoft.com/azuredocs/azure-vote-front:v2 \
--image azure-vote-front:v2Run the command below to validate that the container image has successfully been imported.
az acr repository list --name $ACR_NAME --output tableStep 4: We need to give our AKS cluster access to pull the image from our container registry. We’ll use the managed identity of the cluster. Use the command below to get your managed identity’s ID representing your cluster’s agent pool. From the returned values, copy its principal ID.
az identity list \
--query "[?contains(name,'$AKS_NAME-agentpool')].{Name:name, PrincipalId:principalId}" \
--output tableUse the command below to give the managed identity the AcrPull role on the resource group level. This allows it to pull images from the container registry, which we previously deployed within the same resource group as the AKS cluster. Ensure you’ve adjusted the principal ID before executing the command.
az role assignment create \
--assignee "<principalId>" \
--role "AcrPull" \
--resource-group $RESOURCE_GROUP_NAMEStep 5: The manifest file you’ve downloaded from the GitHub repository uses the image from the example container registry, which most likely won’t exist when you follow these instructions. Open the azure-vote-app.yml manifest file with a text editor or IDE and run the following command to get your ACR login server name:
az acr list --resource-group $RESOURCE_GROUP_NAME --query "[].{acrLoginServer:loginServer}" --output tableReplace acrtaksweuchaosrobino01.azurecr.io with your ACR login server name. The image name is found on line 53 of the manifest file. Provide your own ACR login server name, ensuring your manifest file looks like the following example:
containers:
- name: azure-vote-front
image: <acrName>.azurecr.io/azure-vote-front:v2Step 6: Next, we’ll deploy the application using the kubectl apply command. This command parses the manifest file and creates the defined Kubernetes objects. To do so, we need to get the access credentials for our AKS cluster by running the az aks get-credentials command. Run the commands below—having the folder which holds your manifest file as the working directory.
az aks get-credentials -g $RESOURCE_GROUP_NAME -n $AKS_NAME
kubectl apply -f azure-vote-app.yml --validate=falseThis may take a few minutes to complete. Use the command below to monitor the deployment status.
kubectl rollout status deployment/azure-vote-frontOnce completed, you should have two pods, azure-vote-front and azure-vote-back, in a running state. You can validate this by running the command below.
kubectl get podsStep 7: You should now have a working voting app published to the internet over HTTP. Run the command below.
kubectl get serviceCopy the EXTERNAL_IP of the azure-vote-front service, and paste it into your browser. Congratulations, you’ve now successfully deployed the Azure Voting App.
Set up Chaos Mesh
We must install Chaos Mesh on our AKS cluster to inject faults. Let’s go ahead and install it.
Step 1: Our first step will be adding the chaos-mesh chart repository and ensuring we have the latest update. Run the commands below to add the repository.
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm repo updateStep 2: To scope our Chaos Mesh pods, services, and deployments, we’ll create a separate namespace. Run the command below to create the namespace.
kubectl create ns chaos-testingStep 3: Next, we’ll install Chaos Mesh into the namespace. Run the command below to install chaos mesh to your AKS cluster.
helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-testing --set chaosDaemon.runtime=containerd --set chaosDaemon.socketPath=/run/containerd/containerd.sockThe installation will create multiple pods and services. Validate that the pods are running using the command below.
kubectl get pods -n chaos-testingIf everything went as intended, you’ve successfully installed Chaos Mesh on your AKS cluster.
Onboard the AKS cluster
Azure Chaos Studio cannot inject faults against a resource unless that resource has been onboarded. Using the ARM template you’ve downloaded, we’ll create a target and capability on the AKS cluster resource. In our case, the PodChaos capability represents the Chaos Mesh fault. Run the command below to onboard the AKS cluster to Azure Chaos Studio. Ensure you have the folder that holds the template as your working directory.
$DEPLOYMENT_NAME="OnboardDeploymentRobino-01"
az deployment group create \
--name $DEPLOYMENT_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--template-file "./onboard.json" \
--parameters resourceName=$AKS_NAME resourceGroup=$RESOURCE_GROUP_NAMETo validate the successful onboarding, navigate to Azure Chaos Studio Targets in the Azure Portal, and see if your AKS cluster has the service-direct option enabled.
Create an experiment
Now, we’ll deploy a chaos experiment using the ARM template. The experiment we’ll deploy uses the AKS Chaos Mesh pod faults capability, which will cause a pod fault in the AKS cluster.
Step 1: Open the experiment.json file in your IDE or text editor and inspect it. We will adjust anything. However, it’s good to understand how the deployment works, especially the parts on lines 61 and 62, which contains the jsonSpec. This contains a JSON-escaped Chaos Mesh spec that uses the PodChaos kind. You can use a YAML-to-JSON converter like this one to convert the Chaos Mesh YAML to JSON and minify it, and use a JSON string escape tool to escape the JSON spec. Only include the YAML under the jsonSpec property (don’t include metadata, kind, etc.). As I’ve already done this for you, we’re ready to deploy the template.
Step 2: Add the environment variables, using your terminal from the previous steps. You can use the commands below.
$EXPERIMENT_NAME="exp-t-aks-weu-chaos-pod-robino-01"
$DEPLOYMENT_NAME="ExperimentDeploymentRobino-01"Step 3: Run the following code to deploy the chaos experiment. The deployment should complete in a matter of seconds.
az deployment group create \
--name $DEPLOYMENT_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--template-file "./experiment.json" \
--parameters resourceName=$EXPERIMENT_NAME location=$LOCATION clusterName=$AKS_NAMEYou’ve now successfully deployed your chaos experiment. If you like, you can review your chaos experiment in the Azure Portal before going to the next step.
Step 4: To run the experiment, it needs the permissions for the target resource. More information about the required permissions can be found in the documentation. Run the command below to retrieve the experiment’s ID, so we can use it for assigning the required permissions in the next step.
az ad sp list \
--display-name $EXPERIMENT_NAME \
--query [].id --output tableStep 5: Run the command below to give the experiment the Azure Kubernetes Service Cluster Admin Role on the resource group. Make sure you’ve adjusted the principal ID before executing the command.
az role assignment create \
--assignee "<principalId>" \
--role "Azure Kubernetes Service Cluster Admin Role" \
--resource-group $RESOURCE_GROUP_NAMERun the experiment and evaluate your findings
We’re finally ready to run the freshly created chaos experiment.
Step 1: Go to the Chaos Studio Experiments blade in the Azure Portal, using your browser of choice. Here you’ll find the chaos experiment we’ve created in the previous steps. Open another tab with the application we deployed earlier, using the EXTERNAL_IP of step 7 of the Deploy a web application chapter of this post.
Step 2: Click on the chaos experiment we’ve created in the previous steps, and click Start. It’ll start the following sequence: PreProcessingQueued, PreProcessing, WaitingToStart, and eventually, after about 30 seconds, Running.
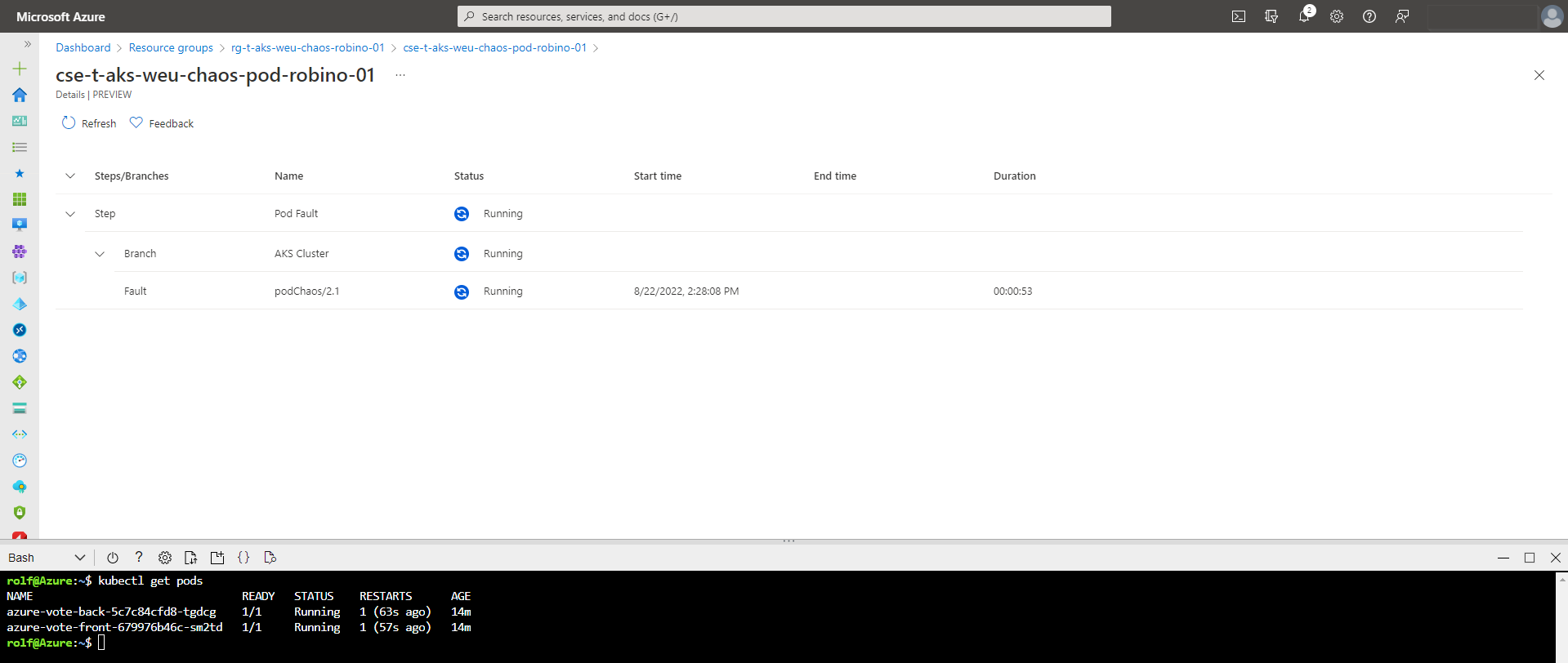
Step 3: While the experiment runs, refresh your web application in the other browser tab. You’ll find that it isn’t working anymore. Since we’re running a controlled and targeted chaos experiment, we know there should be some pod faults within the cluster. Go to your terminal and run the following command:
kubectl get podsYou’ll find that the pods tried to restart themselves. Our experiment continues injecting pod failures.
Step 4: Cancel the experiment, or wait until it has finished after 10 minutes. It should return the Canceled status if you canceled the experiment or the Success status if you let it run for 10 minutes. To make sure, refresh your web application on the other browser tab.
Step 5: Evaluate your findings, learning from them to make your infrastructure and application more resilient. For example, in this particular experiment, we’ve learned that the pod can restore itself. After all, the web app worked perfectly fine after the chaos experiment ended. However, the pod itself is a single failure point as the application runs on a single pod instance. We must add high availability to the solution to make it more resilient.
Running more “What-If” scenarios, translated into chaos experiments, will deliver different results and findings. Bringing chaos engineering to practice will lead you to run multiple chaos experiments on other targets, sequentially and parallel.
Clean up the resources
We will remove all resources created during this guide to save costs and keep an overview of your environment.
Step 1: Remove the resource group, including all the resources. It’ll prompt you for confirmation. When removing the AKS cluster resource, which is included in the deleted resource group, Azure will automatically delete the other resource group (containing the virtual network, load balancer, etc.).
az group delete --name $RESOURCE_GROUP_NAMEStep 2: Finally, log out of the Azure CLI.
az logoutSummary
We went through the Azure Chaos Studio service, compared it to other chaos engineering tools, and created and ran a simple chaos experiment against an AKS cluster. There’s so much more to learn when it comes to chaos engineering. Check out some of these resources to help you forward:
Thank you for taking the time to go through this post and making it to the end. Stay tuned because we’ll keep continuing providing more content on this topic in the future.
This post was originally published on Robino.io.
Author: Rolf Schutten
Posted on: August 25, 2022