From Chaos to Optimum with Azure Chaos Studio
In this article, I’ll explain what Azure Chaos Studio and chaos engineering is, how Azure Chaos Studio can be used to test and improve application resiliency, and share my thoughts on my first hands-on experiences.
About Azure Chaos Studio
At Microsoft Ignite on the 2nd of November 2021, Microsoft has launched Azure Chaos Studio, which has been in Public Preview since. Azure Chaos Studio is an Azure service that helps you to test and improve application resiliency for Azure-based solutions.
What is chaos engineering?
Chaos engineering is a methodology that helps developers attain consistent reliability by hardening services against failures in production. Netflix was one of the first companies to introduce the concept of chaos engineering, using the proprietary and well-known tool Chaos Monkey. The tool intentionally and randomly triggers all kinds of faults. The idea behind this is that the infrastructure has such a robustness level that it is prepared for these real-world scenarios. The goal is to observe, monitor, respond to, and improve your system’s reliability under adverse circumstances.
Another way to think about chaos engineering is that it’s about embracing the inherent chaos in complex systems, and through experimentation, growing the confidence in your solution’s ability to handle the chaos.
What is Azure Chaos Studio?
Azure Chaos Studio is a managed service that uses chaos engineering to help you measure, understand, and improve your cloud application and service resilience. It runs experiments which can simulate faults or cause incidents, such as a region going down or an application failure causing 100% CPU usage of a virtual machine.
Resilience is the capability of a system to handle and recover from disruptions. Application disruptions can cause errors and failures that can adversely affect your business and mission. Whether you’re developing, migrating, or operating Azure applications, it’s important to validate and improve your application’s resilience.
Within Azure Chaos Studio there are three ways to set up Azure Chaos Studio experiments:
- Using service-direct fault, which runs directly against an Azure resource without any need for instrumentation.
- Using agent-based fault, which requires the setup and installation of the chaos agent.
- Using Chaos Mesh, a free, open-source chaos engineering platform for Kubernetes to inject faults into an AKS cluster. Chaos Mesh faults are service-direct faults that require Chaos Mesh to be installed on the AKS cluster.
Chaos in practice
On the documentation page of Azure Chaos Studio, Microsoft has placed three how-to guides to get started with Azure Chaos Studio, for service-direct, agent-based and AKS Chaos Mesh faults. In the following scenarios I use the agent-based and service-direct faults.
The lab environment consists of two Linux (Ubuntu 20.04) virtual machines with Apache web service installed, and are behind a load balancer. They are deployed on a virtual network with a subnet and an associated network security group (to allow HTTP traffic from the Internet, and to allow SSH traffic to the virtual machines from my home network).
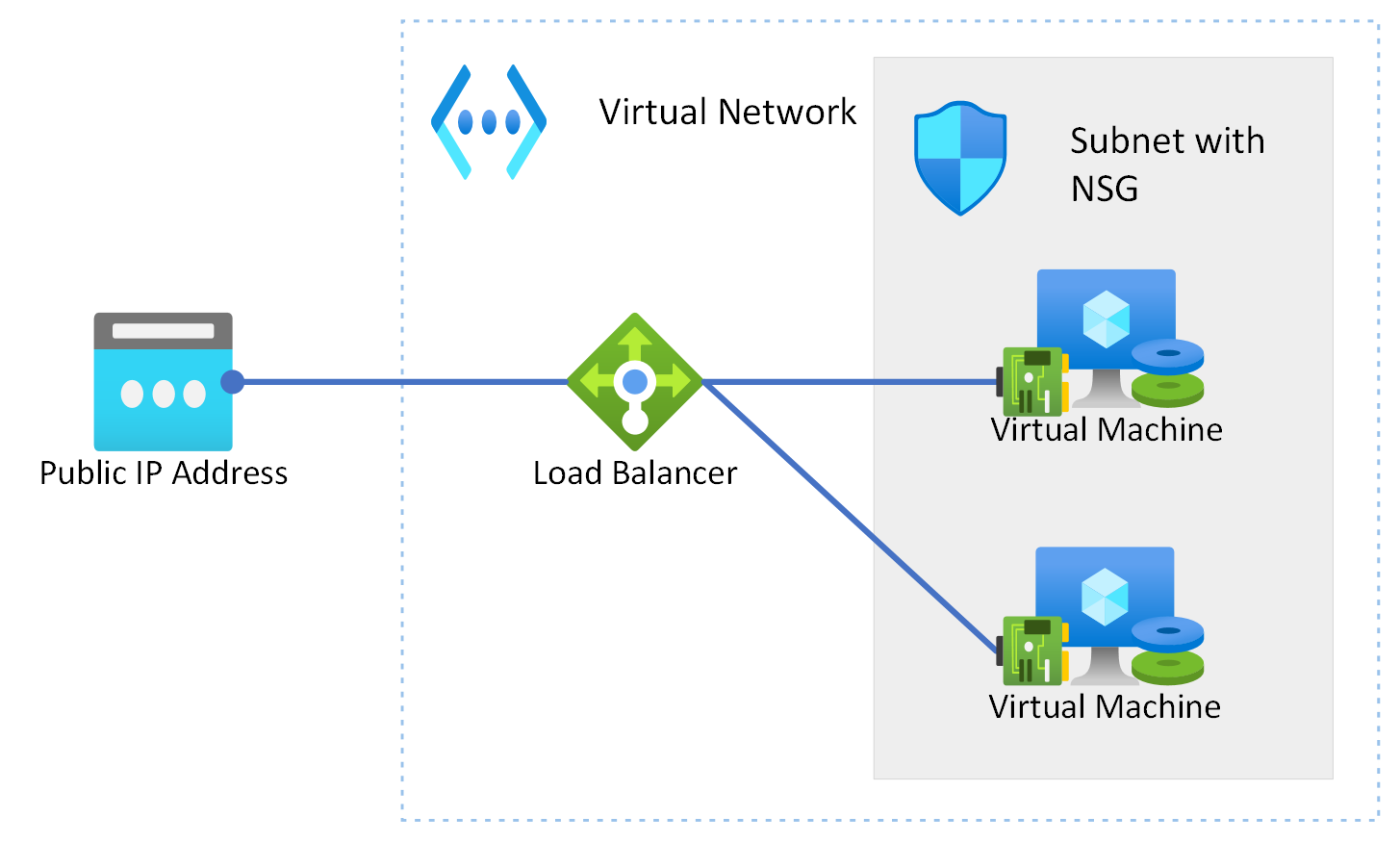
The published page on the virtual machines differ slightly from each other, so that we can see on the respective landing page, which virtual machine is currently responsible for publishing the web page.

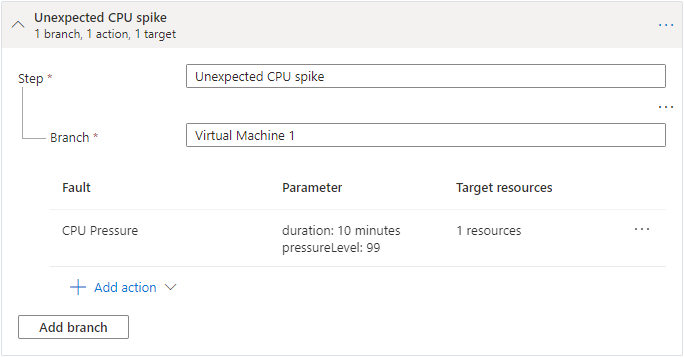
Chaos scenario #1. Unexpected CPU spike
In this scenario, we cause an unexpected CPU spike on one of the virtual machines, to test whether the load balancer settings are optimal and reduce downtime. The Chaos Studio agent for Linux requires stress-ng, an open-source application that can cause various stress events on a virtual machine. You can install stress-ng by connecting to your Linux virtual machine and running the appropriate installation command for your package manager, for example:
sudo apt-get update && sudo apt-get -y install unzip && sudo apt-get -y install stress-ng
The Azure Chaos Studio experiment looks like this:
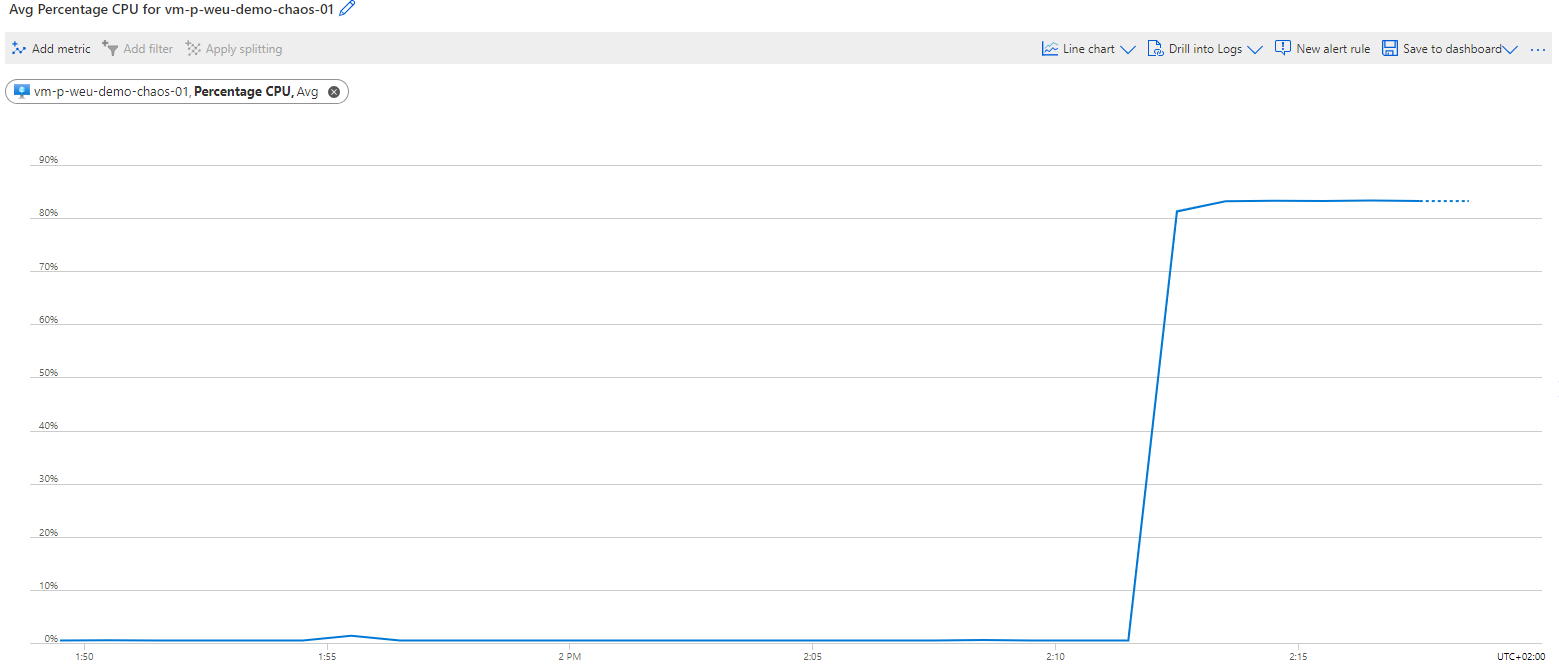
After starting the experiment, the utilization of the CPU increases immediately, stress-ng is clearly doing its job.
When accessing the public IP address of the load balancer, placed in front of the virtual machines publishing the web pages, both web pages (running on different virtual machines) still show up while running the experiment. This is as expected, because the targeted virtual machine is still running and active, and in the lab environment the web pages are accessed via HTTP. HTTP health probes have therefore been set up in the load balancer. With HTTP health probes it’s not possible to balance load based on the CPU utilization of the virtual machines. With HTTPS health probes you can, by adding a customized script to the health probe. In a real world scenario, if load needs to be balanced based on CPU utilization of the underlying virtual machines, an HTTPS health probe must be set up with a custom script.
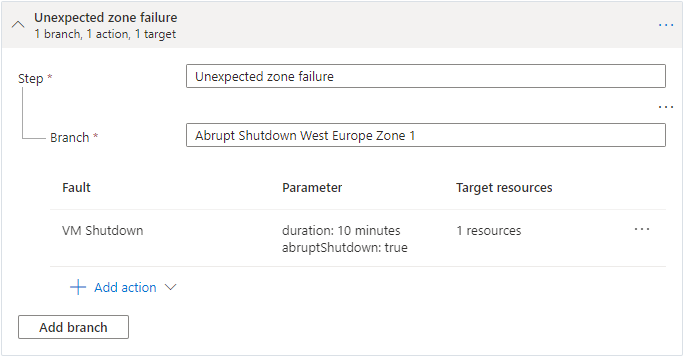
Chaos scenario #2. Unexpected datacenter or zone failure
In this scenario, we cause an unexpected outage of an Azure zone, to test whether placing the VMs in different availability zones does its job and reduce outages. Virtual machine 1 is in availability zone 1, virtual machine 2 is in availability zone 2. The other resources are regional services.
The Azure Chaos Studio experiment looks like this:
After initiating the experiment, the target virtual machine immediately enters a stopped state. When accessing the public IP address of the load balancer, placed in front of the virtual machines publishing the web pages, only one web page (of the non-targeted virtual machines) shows up while running the experiment. This is as expected, because the load balancer routes us to the non-targeted virtual machine, as the configured health probe is giving a negative signal to the load balancer for the target virtual machine.
As soon as the experiment has ended, the target virtual machine will (automatically) be restarted properly and its web page can also be accessed again.
Closing thoughts
When I think of chaos engineering I think of terminating scenario’s in (pre-)production, to validate ensure that engineers implement their services to be resilient to instance failures. This is exactly what Azure Chaos Studio does. Using Azure Chaos Studio is safe and somewhat predictable: your experiment is a workflow, where you determine what the trigger is (and when), that could be part of your build and release pipelines for instance.

Microsoft has built a nice library of standard faults and actions, that will go a long way to help most professionals evaluate the resilience of their infrastructure. That is where the strength of Azure Chaos Studio lies: evaluating and proving against specific scenarios, at a planned time. That can be very valuable for managed service providers (MSPs) and independent software vendors (ISVs). And not unimportant, the integration possibilities in CI/CD pipelines are very promising.
Author: Rolf Schutten
Posted on: July 9, 2022